The math behind AI spreadsheet automation for sales operations teams always looks flawless on day one. A standard grid interface, an OpenAI API integration, and a prompt designed to cleanse unstructured company records seem to offer an immediate escape from manual data cleaning. The initial validation tests on 50 rows deliver perfectly formatted columns.

But as the custom prompt formula is dragged down 10,000 rows, a hidden operational issue surfaces.
Raw API calls executed sequentially or across bulk rows do not understand the structural boundaries of a spreadsheet. What began as a low-cost internal hack rapidly deteriorates into a budget crisis and an acute operational bottleneck.
- Cells time out
- Strict API rate limits freeze critical go-to-market workflows
- Unstructured data returns with broken strings that corrupt the entire sheet structure
Sales ops automation promised to bypass expensive data vendors, but instead, it introduced a new form of technical debt. Resolving this requires moving past the illusion of the direct API-to-spreadsheet connection and understanding the systemic friction of unmanaged Large Language Model (LLM) pipelines.
Why does pipeline visibility decline as sales stacks scale?
The core failure pattern of the DIY spreadsheet pipeline stems from a fundamental structural mismatch: spreadsheets calculate data cell-by-cell, whereas LLMs process text via token blocks.
When a sales operations team inputs a custom prompt formula across thousands of rows, the spreadsheet engine attempts to execute these requests concurrently or in rapid, unmanaged successions. This lack of control triggers a cascade of second-order operational consequences:
- The Token Multiplier Effect: A raw LLM lacks context retention across independent cells. To clean a single company name or determine an industry classification, the entire prompt instruction set, context formatting rules, and system guidelines must be sent for every single row. A ten-thousand-row sheet turns a brief instruction set into millions of redundant input tokens, inflating the API bill exponentially.
- Rate Limit Paralyzation: Commercial API tiers enforce strict limits on Requests Per Minute (RPM) and Tokens Per Minute (TPM). A massive spreadsheet drag-down breaches these thresholds within seconds, causing the API to return error codes that overwrite existing data or halt execution mid-way through a pipeline.
- Structural Corruption: LLMs are non-deterministic. Without strict architectural controls, an API response might include unexpected markdown, trailing commas, or conversational preambles like "Here is the cleaned data:". When dropped into a spreadsheet cell, this unformatted text breaks downstream lookup formulas and invalidates data validation rules.
How do sales ops teams automate Google Sheets without collapsing under these costs?
According to a recent report, building a useful LLM pipeline requires moving away from direct, unmonitored API calls. It demands a structured approach to managing data flow, caching, and prompt engineering before the data ever touches a cell.
What breaks first when outbound teams scale unstructured data?
When the objective shifts from simple text generation to actual sales pipeline intelligence, the question of what is AI-powered data enrichment takes on a stricter operational meaning. It is not merely about appending text; it is about establishing semantic accuracy across a messy go-to-market database. Without a dedicated architecture managing the data flow between the spreadsheet interface and the model, several critical points of failure emerge.
First, prompt drift introduces variable quality.
A prompt that successfully extracts industry classifications for software companies often fails when applied to manufacturing conglomerates, resulting in unverified data artifacts that sales reps unknowingly use during outbound sequences.
Second, there is a total absence of a caching layer.
If a spreadsheet re-calculates due to an accidental filter, column sorting, or page refresh, the entire sheet re-executes the API formulas. The organization pays multiple times to process the exact same data rows.
This operational tension forces a choice between data speed and financial predictability. When raw tokens are consumed irrelevantly by individual cells, the cost of data enrichment begins to exceed the value of the pipeline intelligence generated.
Can Google Apps Script make DIY AI spreadsheet automation more reliable?
A Google Apps Script expert would point out an important distinction:
Google Sheets is not inherently unsuitable for AI workflows. The real failure occurs when thousands of individual cells act as independent LLM clients without any execution control.
Google Apps Script, Google Sheets’ built-in automation tool within Google Workspace, introduces a more structured way to manage OpenAI API integration and AI spreadsheet automation for sales operations teams.
Instead of firing thousands of uncontrolled formula calls simultaneously, Apps Script can introduce operational controls such as:
- Batch Processing: Large spreadsheets can be broken into manageable groups of records, allowing the system to process multiple rows through planned API execution rather than uncontrolled cell-by-cell requests.
- API Rate Limit Management: Scripts can schedule jobs, control execution timing, introduce delays, and prevent sudden bursts that exceed Requests Per Minute (RPM) and Tokens Per Minute (TPM) thresholds.
- Caching and Duplicate Detection: Previously enriched company records can be stored and reused, preventing organizations from paying repeatedly for identical API requests caused by duplicate records or spreadsheet recalculations.
- Error Handling and Retry Logic: Failed requests can be captured, logged, and retried selectively instead of forcing teams to rerun entire sheets and spend additional tokens on completed records.
For smaller enrichment workflows, this approach can significantly reduce token waste and provide more predictable automation.
However, a Google Apps Script expert would also recognize its boundaries. As sales databases expand across thousands of accounts and multiple enrichment requirements, teams must still maintain custom scripts, monitor failures, define output validation rules, and handle ambiguous data cases manually.
The challenge has evolved from controlling API calls to governing data quality at scale. This is where a dedicated orchestration layer becomes necessary.
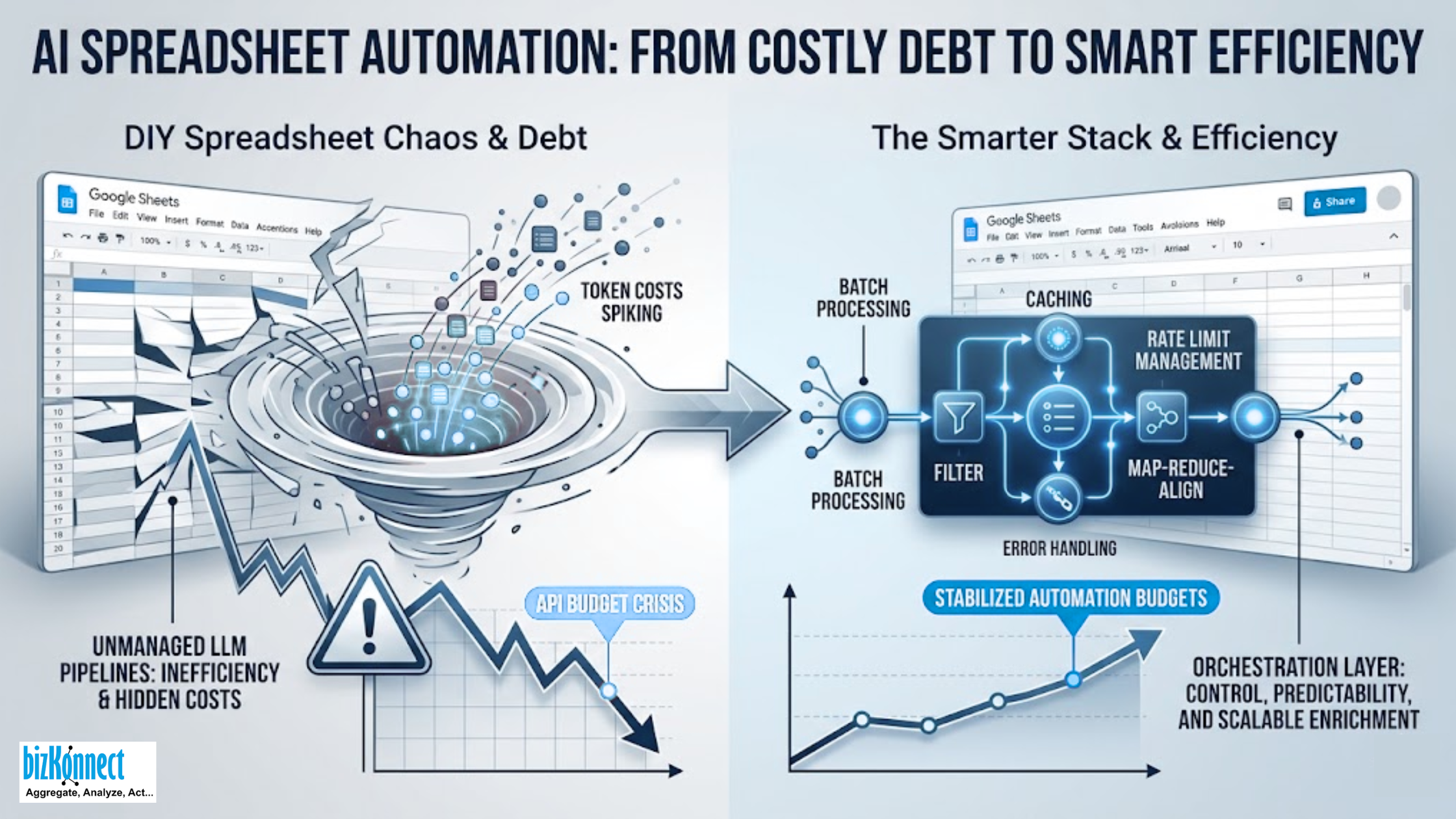
How to shift from raw API tokens to an orchestration layer?
To fix a failing data pipeline, operations leaders must stop viewing the LLM as a standalone engine and start treating it as one component of a broader data system. To build a highly reliable pipeline, architectures must utilize explicit processing stages rather than throwing a single raw prompt at a massive dataset.
A robust pipeline relies on a structural sequence to process information effectively:
- The Map Stage: Instead of feeding a massive, chaotic string into a cell, data must be broken down into short, atomic inputs. Each call operates on a bounded chunk, isolating specific variables (like a raw company description) to emit data candidates small enough to be independently evaluated.
- The Reduce Stage: The system aggregates and deduplicates those isolated candidates across the dataset. This ensures the language model reasons over a constrained, pre-filtered set of structured variables rather than raw, noisy source material.
- The Align Stage: This final tier enforces strict length, format, and semantic rules per output section. It applies hard guardrails to ensure the output matches the required database schema, taking away conversational text and formatting anomalies before the data is written to the cell.
This structural correction transforms the workflow from an unmanaged cash drain into a predictable, scalable infrastructure.
However, automated orchestration layers only solve half the problem. While automated filtering handles the predictable 90% of formatting and scaling, the remaining 10% of complex, nuanced enterprise data introduces edge cases where purely algorithmic systems falter.
The critical integration of human-in-the-loop validation
Because B2B sales intelligence requires absolute accuracy to protect domain reputation and outbound metrics, technology alone is rarely sufficient.
A mature AI operations platform supplements the orchestration layer with an automated, human-in-the-loop cleansing framework. This hybrid approach ensures that low-confidence model outputs, and ambiguous corporate structures are routed to human reviewers rather than polluting the CRM.
Introducing a verification layer directly into the native spreadsheet workflow alters the economic and operational trajectory of data enrichment:
- Elimination of Prompt Bloat: Instead of building massive, multi-shot prompts filled with endless negative constraints to force an LLM to handle rare edge cases, the system prompt remains lean and token-efficient. The model handles the standard, high-volume rows, while humans resolve the exceptions.
- Continuous Feedback Loops: Human corrections do not merely fix the immediate cell; they serve as validated training data that refines downstream prompt logic, systematically reducing model drift and error rates over time.
- Total Financial Predictability: By decoupling raw token consumption from the spreadsheet interface, organizations eliminate the risk of accidental API triggers, runaway recalculation costs, and token waste on corrupted formatting.
Moving away from direct API dependencies allows sales operations teams to reclaim their budgets while securing the clean, structured data required for multi-threaded account targeting.
Let’s address a few Frequently Asked Questions (FAQs)
Q.Why does my Google Sheets OpenAI API integration constantly throw error codes on large datasets?
This occurs because standard spreadsheets execute formulas simultaneously or in rapid, unthrottled batches. This behavior immediately triggers the rate limits (Requests Per Minute and Tokens Per Minute) set by API providers, causing the system to return error codes instead of data.
Q. How do sales ops teams automate Google Sheets without risking high API costs?
Efficient automation requires an intervening architecture that manages data flow. Instead of calling APIs directly from cells, teams utilize an orchestration layer or dedicated data platforms that handle batch processing, implement response caching, and enforce rigid data schemas.
Q. Where does a human-in-the-loop framework fit into automated data cleansing?
The human-in-the-loop framework acts as a validation tier that handles exceptions and low-confidence outputs flagged by the orchestration layer. This ensures absolute data accuracy for complex edge cases without inflating token costs through over-engineered prompts.
Continuing to run unmanaged API calls inside standard spreadsheets is a recipe for escalating overhead and fragmented data systems. True efficiency requires moving away from raw token consumption and adopting systems built for enterprise data integrity.
To see how structured processing and native enrichment can transform your datasets without the technical overhead, CLICK HERE to explore BizKonnect’s advanced automated data solutions and request a free 100-row sample cleanup.
CLICK HERE to know more with BizKonnect.